Business User Guide
There are times when data is sitting in legacy systems and is inaccessible via APIs. Even if the data is available through APIs, it requires a certain amount of conditioning before it can be consumed by your front-end. In this case, Conscia offers the ability to create a schema-agnostic graph that indexes data from various back-end sources and empowers non-technical users to validate, enrich, classify and normalize the data. This data in the DX Graph is available via real-time APIs to any client application. Conscia also offers the ability to push this data to any application via APIs, webhooks and file-based batch methods.
Navigating the DX Graph UI
Every customer application can have a slightly different navigation structure depending on the capablities required and the workflows that need to be enabled. This includes labeling differences such Data vs. Content, Classification vs. Taxonomies.
The DX Graph UI has the following pages:
- Sources / Content
- These are data collections synced directly from source systems through the data load process.
- Master
- There are times when you need to unify data from multiple collections to create a master data record. For example, you may want to master a product record by pulling product information from a PIM, inventory and availability information from the ERP, product content from a CMS. You would create Master collections for such data and those collections would appear on this tab.
- Taxonomies / Classification
- On this page, you can manage taxonomy values for the various Taxonomy Data Collections. You can then apply the taxonomy to a target Data Collection on this page as well.
- Files
- Here you can upload files and manually run jobs that have been registered and/or scheduled within the DX Graph
- Data Validation
- Conscia offers configurable Inspector Cards which help users understand the quality of their data and identify areas where it can be improved. This page allows you to configure these inspector cards for each Data Collection.
- Data Model
- Here you can update the data model as well as the relationships between Data Collections.
- Navigation Management
- On this page, you can manage what data collections show up on your Mastes and Sources pages.
- User Groups Membership
- Here, you control the user groups that each user should belong to. Note that users are currently created via API only, however, you can add a user to a pre-existing User Group via self-service UI here.
Exploring Data from Source Systems
A list of data sources can be found within the 'Sources' or 'Content' tab in the top navigation.
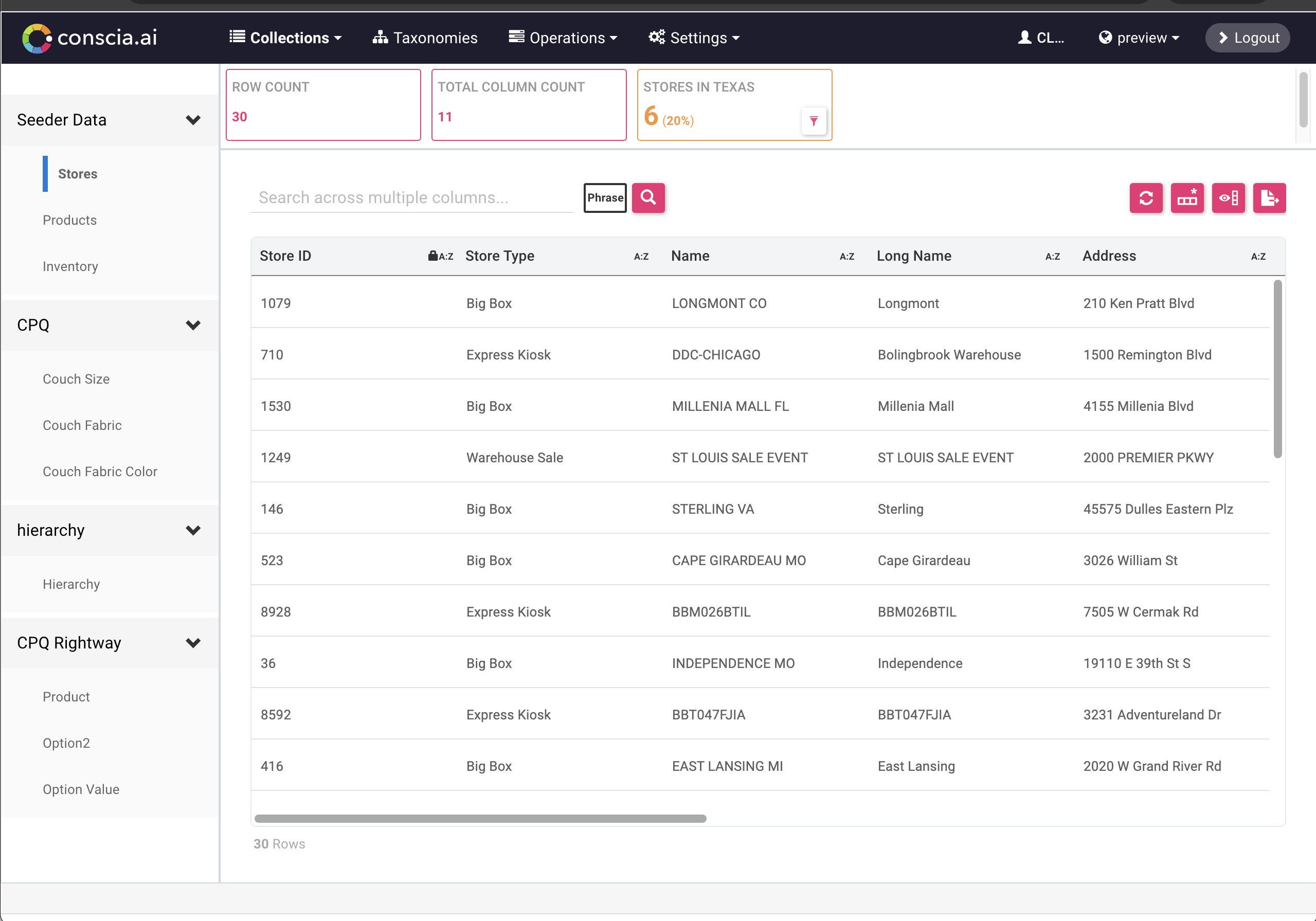
- Clicking on a Data Collection will display a grid with the data records that exist within the Data Collection as well as the inspector cards that have been configured.
- Selecting a record from the grid will bring up the record details in the record widget (bottom pane).
Data Collections
In DX Graph, data resides in Data Collections. A Collection contains records of a certain user-defined type, such as customers, products, stores, or categories.
Collections can be used to manage and/or analyze various types of data such as:
- Master data (e.g. Customers, Stores, Products, Promotions).
- Lookup data (e.g. Customer Types, Regions, Countries, Colours). When editing a record in another Collection via the DX Graph UI, a drop-down list may be presented that is populated by the data records in a Lookup Collection.
- Categorization data (e.g. Customer Audiences/Segments, Product Categories). Categorization data can be configured to hierarchical (i.e. records may have a parent record).
Collections may also fall under more than one of the above types of data.
Key Capabilities of DX Graph
Connect Data Between Data Collections
Search And Filter Data
Validate Data with Inspector Cards
Structure Data with Schema Management
Label Data with Taxonomies
Relate Data with Hierarchies
Classify Data with Hierarchical Taxonomies
Enrich and Normalize Data
Distribute Data in the DX Graph to Downstream Applications
There are four ways to access data in the DX Graph:
- Real-time APIs
- Export a data collection from the DX Graph UI using the Export function at a Data Collection level
- Export a data collection using an API endpoint (Documentation coming soon)
- Set up a Webhook to be notified of changes within a data collection