Job Types
Conscia offers several out of the box Job Types that you can use to instantiate a Job, and optionally, schedule it. Each of these Job Types can be run completely independently of each other, although some have overlapping functionality.
Running Jobs
Any given Job can be set in a Job definition or run directly.
To create a Job definition, use the API detailed here. The Job Type is defined in the jobType property and the specific Input Parameters associated with each Job Type described below are defined in the params object.
To run a Job directly, use the Job Types _execute endpoint detailed here. The jobType is set in the URL path, and the rest of the Input Parameters are defined in the params object. For example,
POST {{engineUrl}}/job-types/exportCollection/_execute
Content-Type: application/json
X-Customer-Code: {{customerCode}}
Authorization: Bearer {{apiKey}}
{
"params": {
"collectionCode": "movie",
"targetBucketCode": "processed",
"filenamePattern": "movies.jsonl"
}
}
Import Data Files
| Job Type Code | Description |
|---|---|
| importDataFiles | The Import Data Files job validates Data Files (like the Validates Data Files job) and imports them into a Data Collection. Depending on whether the Data Files were successfully imported, they can be moved to different Buckets. These Buckets are specified in the Job definition. It also provides an option to transform the data before loading it into the Data Collection. |
For more information on how to generally work with data files, please see the documentation here.
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| incomingBucketCode | Yes | The DX Graph Bucket that contains the Data Files specified by Filename Pattern. |
| skippedBucketCode | Yes | A file that has been skipped due to Process Last Matched File is true will be moved here. It will not be validated. |
| processedBucketCode | Yes | A file that is fully imported into a collection with no validation errors is moved here. A file that has any validation errors with Skip Invalid Records is true will be moved here along with the corresponding error files. |
| invalidBucketCode | Yes | This is mandatory if Skip Invalid Records is false. A file that has any validation errors when Skip Invalid Records is false will be moved here along with the corresponding error files. |
| filenamePattern | Yes | Groups files into a set of files to be processed together. e.g. products_*.csv |
| recordIdentifierField | Yes | Indicates which field uniquely identifies the records in the Data Files. Validation errors use this to point out erroneous records. |
| parseOptions | Yes | Configures how to parse the Source Data Files. e.g. Are the files delimited vs Excel vs JSON format? |
| collectionCode | Yes | The Data Collection to import Data Files into |
| sourceSchema | No | The JSON Schema that must be conformed to. |
| targetSchema | No | JSON schema that is applied to the transformed records. Default: uses the schema of specified Collection Code. |
| transformers | No | A list of transformations applied to each validated source record. |
| skipInvalidRecords | No | Default: false. If false, if any validation errors occurred, no data will be imported. |
| processLastMatchedFile | No | Data Files are scanned in alphabetical order so that you are able to use filenames to sequence the processing sequence. If this parameter is set to true, then only the last matching Data File will be processed and the previous files will be skipped. |
| ifExists | No | Options: merge or replace. Default: merge. |
| ifNotExists | No | Options: create, fail, or ignore. Default: create. |
| skipEventEmission | No | When skipEventEmission is set to true any triggers for DataRecordCreated, DataRecordUpdated or DataRecordRemoved for the target Collection will not fire. It is useful (and faster) when performing bulk inserts/updates where you know you do not want to process those triggers. |
To execute this job directly against a Data Bucket:
POST {{engineUrl}}/buckets/{{incomingBucketCode}}/files/_import
Content-Type: application/json
X-Customer-Code: {{customerCode}}
Authorization: Bearer {{apiKey}}
{
"skippedBucketCode": "skipped",
"processedBucketCode": "processed",
"invalidBucketCode": "invalidated",
"filenamePattern": "articles_*.jsonl",
"skipInvalidRecords": false,
"recordIdentifierField": "article_id",
"collectionCode": "contentful-articles",
"parseOptions": {
"format": "JSONL"
}
}
Validate Data Files
| Job Type Code | Description |
|---|---|
| validateDataFiles | The Validate Data File job ensures that a set of Data Files (specified by a filename pattern) is parseable and conforms to a specified schema. Depending on whether the Data Files were successfully validated, they can be moved to a specified data Bucket. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| incomingBucketCode | Yes | The DX Graph Bucket that contains the Data Files specified by Filename Pattern. |
| validatedBucketCode | Yes | If this is specified, successfully validated Data Files are moved to this Bucket. |
| invalidBucketCode | Yes | If this is specified, unsuccessfully validated Data Files are moved to this Bucket. |
| filenamePattern | Yes | Groups files into a set of files to be processed together. e.g. products_*.csv |
| sourceSchema | No | The JSON Schema that must be conformed to. |
| recordIdentifierField | Yes | Indicates which field uniquely identifies the records in the Data Files. Validation errors use this to point out erroneous records. |
| parseOptions | Yes | Configures how to parse the Source Data Files. e.g. Are the files delimited vs Excel vs JSON format? |
| collectionCode | Yes | The Data Collection to import Data Files into |
| transformers | No | A list of transformations applied to each validated source record. |
| targetSchema | No | JSON schema that is applied to the transformed records. Default: uses the schema of specified Collection Code. |
To execute this job directly against a Data Bucket:
POST {{engineUrl}}/buckets/{{incomingBucketCode}}/files/_validate
Content-Type: application/json
X-Customer-Code: {{customerCode}}
Authorization: Bearer {{apiKey}}
{
"validatedBucketCode": "validated",
"invalidBucketCode": "invalidated",
"filenamePattern": "articles_*.jsonl",
"recordIdentifierField": "article_id",
"collectionCode": "contentful-articles",
"parseOptions": {
"format": "JSONL"
}
}
Transform Data Files
| Job Type Code | Description |
|---|---|
| transformDataFiles | This job type is used validate (like the Validates Data Files job) and transform Data Files. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| sourceBucketCode | Yes | The DX Graph Bucket that contains the Data Files specified by Filename Pattern. |
| targetBucketCode | Yes | A file with no validation errors is moved here or (a file that has validation errors with Skip Invalid Records is true) will be moved here along with the transformed file and any corresponding error files. The transformed files will be JSONL format and will have the filename: {{sourceFilename}}.YYYYMMDD_HHmmss.transformed.jsonl where YYYYMMDD_HHmmss is the timestamp of when the file was generated. |
| invalidBucketCode | Yes | This is mandatory if Skip Invalid Records is false. A file that has any validation errors when Skip Invalid Records is false will be moved here along with the corresponding error files. |
| filenamePattern | Yes | Groups files into a set of files to be processed together. e.g. products_*.csv |
| sourceSchema | No | The JSON Schema that must be conformed to. |
| recordIdentifierField | Yes | Indicates which field uniquely identifies the records in the Data Files. Validation errors use this to point out erroneous records. |
| parseOptions | Yes | Configures how to parse the Source Data Files. e.g. Are the files delimited vs Excel vs JSON format? |
| transformers | No | A list of transformations applied to each validated source record. |
| targetSchema | No | JSON schema that is applied to the transformed records. Default: uses the schema of specified Collection Code. |
| skipInvalidRecords | No | Default: false. If false, if any validation errors occurred, no data will be imported. |
To execute this job directly against a Data Bucket:
POST {{engineUrl}}/buckets/{{incomingBucketCode}}/files/_transform
Content-Type: application/json
X-Customer-Code: {{customerCode}}
Authorization: Bearer {{apiKey}}
{
"targetBucketCode": "processed",
"invalidBucketCode": "invalidated",
"filenamePattern": "articles_*.jsonl",
"recordIdentifierField": "article_id",
"collectionCode": "contentful-articles",
"parseOptions": {
"format": "JSONL"
}
}
The following diagram shows how the Data File jobs fit into the overall Data File processing workflow.
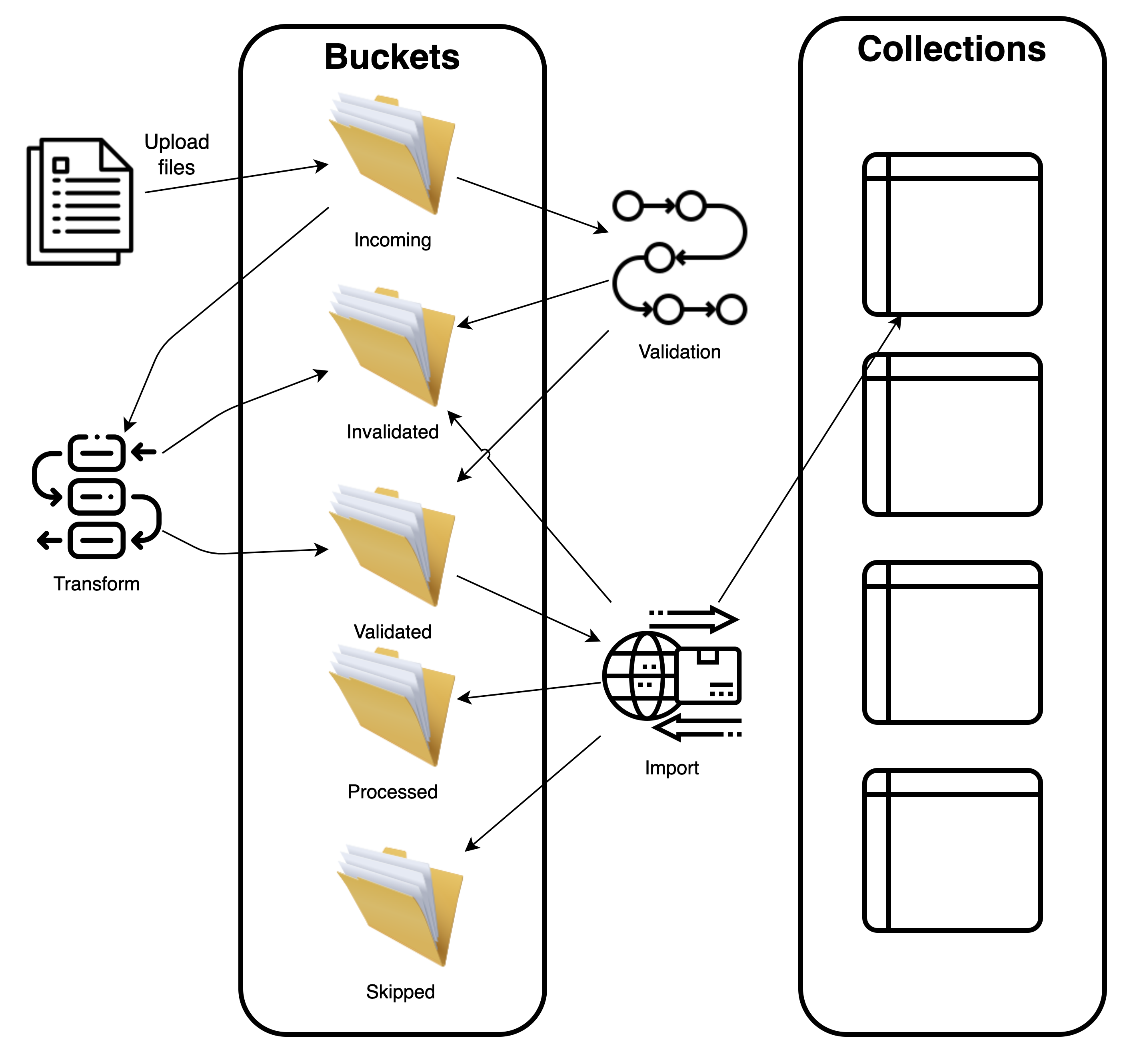
Call Webservice Endpoint
| Job Type Code | Description |
|---|---|
| callWebserviceEndpoint | This job type is used to call a webservice endpoint. It can be used to call any webservice endpoint, including REST and GraphQL, using any HTTP method (e.g. POST, PATCH, DELETE, PUT, etc.) The job type supports GET, POST, PUT, and DELETE HTTP methods. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| url | Yes | The URL of the webservice endpoint to call. |
| method | Yes | The HTTP method to use when calling the webservice endpoint. |
| headers | No | The headers to include in the request. |
| body | No | The body to include in the request. |
| searchParams | No | The query parameters to include in the request. |
Call DX Engine
| Job Type Code | Description |
|---|---|
| callDxEngine | This job type is used to call DX Engine. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| templateCode | Yes | The DX Engine Template to invoke. |
| context | No | The context to include in the request. |
Process File With Webservice Endpoint
| Job Type Code | Description |
|---|---|
| processFileWithWebserviceEndpoint | The Job Type Process File With Webservice Endpoint is used to process a file and send the records to a webservice endpoint. The file can be any delimited file and JSON (array or newline-delimited). The job type supports sending batches of records to the webservice endpoint. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| dataBucketCode | Yes | The data bucket code containing the file to process. |
| filename | Yes | The file that contains the records to process. This can be any delimited file and JSON (array or newline-delimited) |
| batchSize | No | The batch size to use. Defaults to 1. A batch of 3 will send an array of 3 JSON records to the webservice. |
| webserviceEndpoint | Yes | The webservice endpoint to call. This is an object. All of the webservice properties can contain a JavaScript expression (within backticks) that have reference to a variable called records which is the array of of records in the file. |
| webserviceEndpoint.url | Yes | The URL of the webservice endpoint to call. |
| webserviceEndpoint.method | Yes | The HTTP method to use when calling the webservice endpoint. |
| webserviceEndpoint.headers | No | The headers to include in the request. |
| webserviceEndpoint.body | No | The body to include in the request. |
| webserviceEndpoint.searchParams | No | The query parameters to include in the request. |
Example:
Take the following CSV file: people.csv
name,email
John Doe,john@email.com
Jane Doe,jane@email.com
Jim Doe,jim@example.com
Jill Doe,jill@example.com
The following parameters will send batches of two JSON records to a webservice endpoint.
{
"dataBucketCode": "my-data-bucket",
"filename": "people.csv",
"batchSize": 2,
"webserviceEndpoint": {
"url": "https://my-webservice.com/api/v1/records",
"method": "`records[0]method`",
"headers": {
"Content-Type": "application/json"
},
"body": {
"data" : "`records`",
"length": "`records.length`"
}
}
}
The body of each request will be:
{
"data": [
{ "name": "John Doe", "email": "john@email.com" },
{ "name": "Jane Doe", "email": "jane@email.com" }
],
"length": 2
}
followed by:
{
"data": [
{ "name": "Jim Doe", "email": "jim@example.com" },
{ "name": "Jill Doe", "email": "jill@example.com" }
]
"length": 2
}
Process File With DX Engine
| Job Type Code | Description |
|---|---|
| processFileWithDxEngine | The Job Type Process File With DX Engine is used to process a file and send the records to a DX Engine. The file can be any delimited file and JSON (array or newline-delimited). The job type supports sending batches of records to the DX Engine. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| dataBucketCode | Yes | The data bucket code containing the file to process. |
| filename | Yes | The file that contains the records to process. This can be any delimited file and JSON (array or newline-delimited) |
| batchSize | No | The batch size to use. Defaults to 1. A batch of 3 will send an array of 3 JSON records to the webservice. |
| environmentCode | Yes | The DX Engine environment code to use. |
| token | Yes | The DX Engine token to use. |
| templateCode | Yes | The DX Engine template to invoke. |
| context | No | The context to include in the request. It defaults to {}. |
Both templateCode and context can contain a JavaScript expression (within backticks) that has a reference to a variable called records which is the array of records in the file. For example,
"templateCode": "`'template_' + records[0].name`"
or
"context": {
"data": "`records[0]`"
}
Process Collection With Webservice Endpoint
| Job Type Code | Description |
|---|---|
| processCollectionWithWebserviceEndpoint | The Job Type Process Collection With Webservice Endpoint is used to process a DX Graph Collection and send the records to a webservice endpoint. The job type supports sending batches of records to a webservice endpoint. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| collectionCode | Yes | The data bucket code containing the file to process. |
| filter | No | The filter to apply to the collection. |
| batchSize | No | The batch size to use. Defaults to 1. A batch of 3 will send an array of 3 JSON records to the webservice. |
| webserviceEndpoint | Yes | The webservice endpoint to call. This is an object. All of the webservice properties can contain a JavaScript expression (within backticks) that have reference to a variable called records which is the array of of records in the file. |
| webserviceEndpoint.url | Yes | The URL of the webservice endpoint to call. |
| webserviceEndpoint.method | Yes | The HTTP method to use when calling the webservice endpoint. |
| webserviceEndpoint.headers | No | The headers to include in the request. |
| webserviceEndpoint.body | No | The body to include in the request. |
| webserviceEndpoint.searchParams | No | The query parameters to include in the request. |
Process Collection With DX Engine
| Job Type Code | Description |
|---|---|
| processCollectionWithDxEngine | The Job Type Process Collection With DX Engine is used to process a DX Graph Collection and send the records to a DX Engine. The job type supports sending batches of records to the DX Engine. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| collectionCode | Yes | The data bucket code containing the file to process. |
| filter | No | The filter to apply to the collection. |
| batchSize | No | The batch size to use. Defaults to 1. A batch of 3 will send an array of 3 JSON records to the webservice. |
| environmentCode | Yes | The DX Engine environment code to use. |
| token | Yes | The DX Engine token to use. |
| templateCode | Yes | The DX Engine template to invoke. This can contain a JavaScript expression (within backticks) that has a reference to a variable called records which is the array of batched records (based on batchSize) in the collection. |
| context | No | It defaults to {}. The context to include in the DX Engine request. This can contain a JavaScript expression (within backticks) that has a reference to a variable called records which is the array of batched records (based on batchSize) in the collection. |
Download Data From Webservice
This Job Type is covered here.
Export Collection To File
Collection data can be exported to a file in a Data Bucket. This mechanism is useful for exporting data to be consumed by another system such as a search engine, database, data warehouse, etc.
The Export Collection job exports every record from a Collection that matches a specified filter (if provided) into a file in a Data Bucket. Any transformation or schema errors are uploaded to an errors file in the same Data Bucket. More details on error files are here. Exported files are in line-delimited JSON format.
| Job Type Code | Description |
|---|---|
| exportCollection | The Job Type Export Collection is used to export data from a Collection into a file in a Data Bucket. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| collectionCode | Yes | The Collection to export from. |
| targetBucketCode | Yes | The DX Graph Bucket that the Data File will be exported to. |
| filenamePattern | Yes | The name of the file that the data will be written to. You can use the placeholder {{timestamp}} to include the timestamp of the export request. Example: products_{{timestamp}}.jsonl would result in files that look like: products_20230514_131001.jsonl. See Filename Patterns for more information. |
| filter | No | A DX Graph filter that will be applied to the source records. If a filter is not provided, then all records will be exported. |
| recordLayoutConfig | No | If this is specified, the export of the records are in the Expanded Record Format. This defines what fields and relationships to return. You can see details here. If not specified, the records are exported as-is. |
| limit | No | The number that number of records that should be exported. If a limit is not provided, then all records will be exported. |
| transformers | No | An array of transformations applied to each source record in the collection. |
For examples on the use of filter, recordLayoutConfig, and limit, see Querying DX Graph Collections.
When specifying any transformers, you must keep in mind that the source record is in the Expanded Record Format. The transformers have access to Expanded Record Format functions
Upload Data to Azure Blob Storage
| Job Type Code | Description |
|---|---|
| uploadToAzureBlobStorage | The Job Type Upload Data to Azure Blob Storage is used to upload files into a storage container in Azure. |
Input Parameters
| Parameter | Required | Description |
|---|---|---|
| customerCode | Yes | The customer code of this instance. |
| azureConnectionString | Yes | The Azure blob storage connection string. |
| sourceBucketCode | Yes | Conscia bucket to look into. |
| filenamePattern | Yes | Groups files into a set of a files to be processed together. See File Name Patterns here. |
| azureContainerName | Yes | The Azure folder/container to upload files into. |